
[Tensorflow] 09 딥러닝에서 Vanishing gradient, Overfitting 해결하기
01. Geoffrey Hinton
이전 시간에도 보았듯이 딥러닝에서 깊이가 깊어질수록 Vanishing gradient로 인해 오히려 학습이 안되는 이유를 살펴보았습니다. 이에 덧붙여 그 해결방법으로 Sigmoid 함수였던 Activation function을 바꿔주면 된다고 언급하였습니다. Hinton 교수님은 이를 포함하여 딥러닝이 일시적으로 한계에 봉착한 이유 4가지를 정리하였습니다.
(1) Our labeled datasets were thousands of times too small.
(2) Our computers were millions of times too slow.
(3) We initailized the weights in a stupid way
(4) We used the wrong type of non-linearity.
1번과 2번은 머신러닝을 코딩하는 입장에서 어떻게 해볼 수 있는 것이 아니라고 생각합니다. 3번과 4번의 이유를 해결함으로써 제대로 된 딥러닝이 이루어지도록 해보고자 합니다.
02. ReLU: Better function

위에서 보듯이 Sigmoid 함수는 0과 1로 근접하는 형태를 가집니다. 다시 말해 함수값은 무조건 0과 1 사이에만 존재합니다. 이것이 지난 포스트에서 학습의 깊이가 깊어질수록 곱셈 연산으로 인해 최종값이 작아지는 이유라고 말하였습니다.
해결방법은 꽤나 간단합니다. Sigmoid 함수와 생김새는 비슷하지만 최대값이 제한되어있지 않은 함수를 찾으면 되는 것입니다.
가장 먼저 고안되었고 가장 흔하게 쓰이는 것이 ReLU 입니다. ReLU를 사용하여 코드를 짤 경우 Layer가 많다해도 정확도가 1.0에 가까워지는 것을 보실 수 있습니다. 다만 마지막에는 Sigmoid의 특성을 활용하여 Cost를 줄여주어야 하기 때문에 마지막 Layer의 학습 시에는 0~1 사이의 값으로 제한하는 Sigmoid 함수를 사용해주어야 합니다.
03. Initializing weights in a smart way
01) Restricted Boatman Machine(RBM)
생각보다 원리는 단순하지만 코드로 짜기가 매우 복잡해보여서 이번에는 그냥 넘어가도록 하겠습니다.
02) Xavier/He initialization
실습 포스트에서 구현해보도록 하겠습니다.
04. Overfitting
Overfitting 역시 올바른 학습을 방해하는 요소 중 하나입니다. Overfitting이란 말그대로 너무 잘 맞아떨어진다는 뜻입니다. 잘 맞으면 좋은 것 아닌가 할 수도 있겠지만 Training Data에는 잘 맞는 반면 Test Data는 잘 맞추지 못하는 것이 문제점입니다.
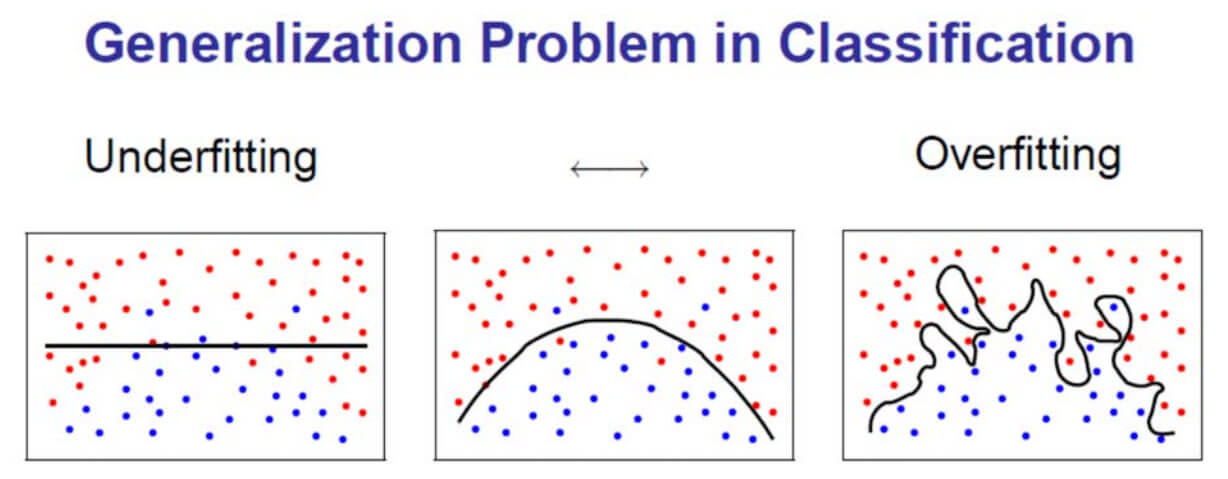
각각의 점들을 Training Data라고 합시다. 왼쪽처럼 너무 안맞는 것도 문제이지만 오른쪽처럼 모델이 너무 세세하게 구성되는 것도 문제입니다(인간답지 못하다는 생각이 들었는데 두번 생각해보니 꽤나 역설적이네요). 저렇게 될 경우 Test Data의 빨간 점이 모델 안쪽에 포함될 가능성이 큽니다. 오히려 정확도가 떨어지겠지요. Training Data가 일부 맞지 않더라도 실전에서 더 높은 정확도를 보이는 것은 가운데의 모델입니다.
01) Regularization
해결방법은 꽤나 단순합니다. 파란색과 빨간색의 영역을 정확하기 위해 데이터를 표준화 시키는 것입니다. 정규화의 일레인 표준화를 시키는 방법은 불러온 데이터를 MinMaxScaler() 함수에 대입하는 것입니다. 이 함수를 거치게 되면 데이터의 값이 1과 -1 사이의 값으로 변환됩니다.
또다른 방법인 L2 regularization은 weight가 너무 큰 값을 갖지 않도록 하는 것입니다.
위의 식처럼 말입니다. 사실 이해가 잘 안되어서 얼렁뚱땅 넘어가려 합니다.
02) Dropout
학습 과정에서 몇개의 Node를 제외하고 학습을 진행하는 것을 의미합니다. “뱃사공이 많으면 배가 산으로 간다”는 말처럼 학습 시에는 일부 Node를 쉬게 하는 것이 오히려 학습에 더 도움이 됩니다. 집중할 부분에 집중하게 되니깐요. 다만 실제 Test 과정에서는 모든 Node를 참여시켜 정확도를 최대로 끌어올립니다. 코딩으로 구현이 쉽기 때문에 실습 때 해보기로 하겠습니다.