
[Tensorflow] 10 Convolutional Neural Networks(CNN) 학습하기

이론
01. Convoluted Neural Network(CNN) 이해하기
Convoluted Neural Network(CNN)의 핵심은 사진을 학습한다는 것입니다. Input으로 Label이 붙은 이미지 파일을 주고 수많은 이미지를 학습시켜 추후에 새로운 이미지가 입력되었을 때 정확히 Label을 붙이는 것을 목적으로 합니다. 예를 들어 강아지, 고양이, 새 등 여러 동물들의 이미지를 보여주고 새로운 강아지의 이미지를 입력하였을 때 학습된 컴퓨터가 해당 이미지를 강아지라고 판단하게 하는 것이 CNN의 목적입니다. CNN은 생명체가 시각 정보를 처리하는 방식을 그대로 이용하고 있습니다. 우리가 무언가 사물을 볼 때 우리의 뇌는 사물을 부분적으로 인식하여 처리한 후 통합하여 하나의 이미지를 만들어냅니다. CNN에서 역시 동일합니다. 이미지를 한쪽 구석에서부터 읽어나가 반대쪽 구석까지 차례차례 작은 이미지들로 읽어낸 후 각각을 처리하여 마지막에 통합하는 과정을 거칩니다.
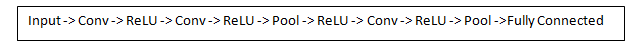
CNN의 기본 골격은 위와 같습니다. 크게 Convolutional layer(Conv), Pooling layer(Pool), ReLU layer(for nonlinearity), Fully connected layer(FC)로 나뉠 수 있습니다. 각각에 대해 하나씩 살펴보도록 하겠습니다.
02. Data(Input & Output)
우선 CNN에 Input과 Output 데이터의 구조부터 살펴보겠습니다. Input은 이미지입니다. 이미지의 구조는 3개의 숫자로 표현될 수 있습니다. 3차원 배열로, 가로(width) x 세로(height) x 색깔(depth)의 의미를 지닙니다. 가로와 세로는 말그대로 이미지의 크기를 나타내고 세번째 항은 색이 있는 이미지인지 여부를 나타냅니다. 이 값이 1이라면 흑백 이미지, 3(RGB)이라면 컬러 이미지를 의미합니다. 예를 들어 배열의 각 항들은 0~255 사이의 값을 가지고 있습니다. (x, y, 0)은 R의 정보를, (x, y, 1)은 G의 정보를 (x, y, 2)는 B의 정보를 담는 식입니다.
Output은 해당 이미지가 어떤 Label을 가질 확률로 제시됩니다. FC layer에서는 Softmax classification을 이용하여 해당이미지가 결국 어떤 Label을 가질 가능성이 높은지를 나타내주게 됩니다.
03. Layer <fn>https://www.slideshare.net/leeseungeun/cnn-vgg-72164295</fn>
01) Convolutional layer(Conv)
(1) Filter
본격적으로 Layer에 대해 살펴보겠습니다. 먼저 Convolutional layer입니다. 이름에서도 알 수 있듯이 CNN의 핵심이 되는 Layer입니다. Conv는 이미지의 특성을 뽑아내는 Layer라고 할 수 있습니다. 아래 이미지는 Conv의 원리를 그대로 보여주고 있습니다.
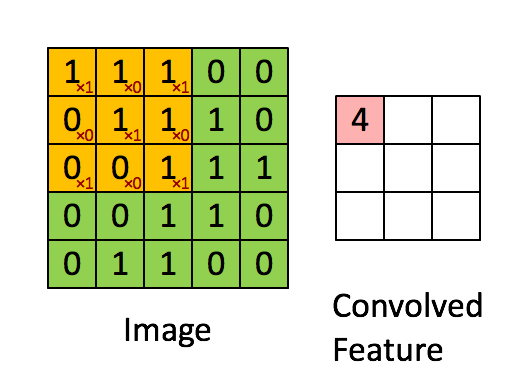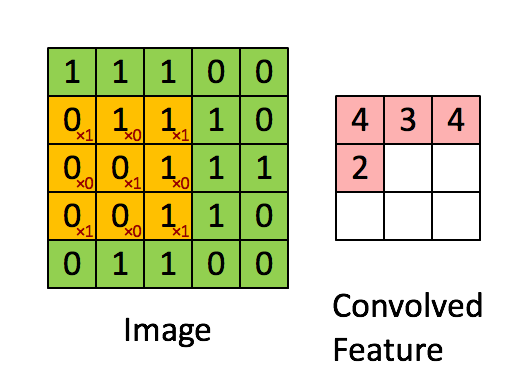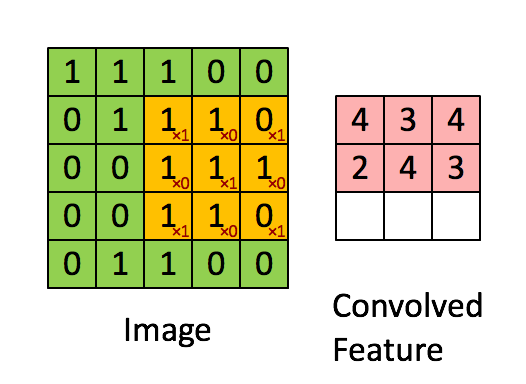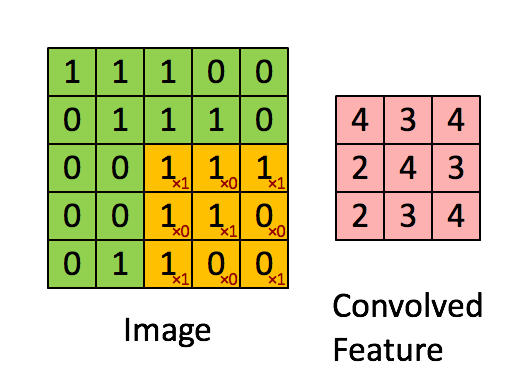
Input된 이미지에 Filter를 이용하여 이미지의 특성을 뽑아내고 있습니다. 여기서 Filter는 빨간색 숫자로 표시된 를 의미합니다.(Filter를 다른 말로 Kernel, Neuron이라고도 합니다. 또한 Filter가 비추는 영역을 가리켜 Receptive field라고 합니다.) Filter는 2차원 배열입니다. 다만 R, G, B 정보를 담은 2차원 배열에서 각각 정보를 추출해야하기 때문에 컬러 사진(Depth = 3)에서는 Filter의 Depth 역시 3이 됩니다. 위 그림에서 Filter는 정확히 1칸씩 움직이며 정보를 추출해내고 있습니다. 움직이는 칸수를 Stride라고 합니다. 필터를 통해 추출해낸 숫자를 담은 배열을 Activation map이라고 부릅니다. Activation map의 개수는 사용한 Filter의 개수와 같습니다.
Filter는 이미지에서 정보를 추출하는 Feature identifier라고 하면 이해하기 쉬울 것입니다. 예를 하나 들어보겠습니다. <fn>https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner’s-Guide-To-Understanding-Convolutional-Neural-Networks/</fn>
* 예시
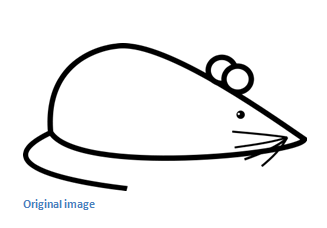
다음과 같은 귀여운 쥐의 이미지가 Input으로 주어졌습니다. 우리는 Filter를 이용하여 이미지의 정보(Feature)를 추출해낼 것입니다.
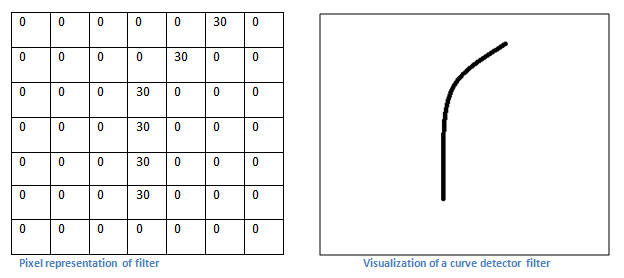
여러 종류의 Filter를 쓸테지만 가장 먼저 이와 같은 Filter를 사용할 것입니다.
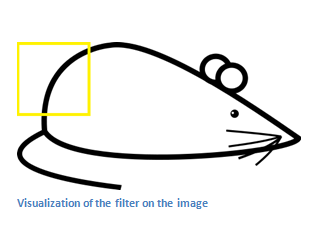
먼저 왼쪽에서부터 Filter에 들어맞는 Feature가 있는지 살펴보겠습니다. 위 그림에서 노란색으로 표시된 Receptive field에 Filter를 가져다대보겠습니다.
계산값(6600)이 매우 크게 나옵니다. 이 말은 해당 Receptive field에 Filter에 담긴 정보가 존재한다는 뜻입니다.

이와 반대로 오른쪽 귀퉁이의 Receptive field에 Filter를 가져다대봤더니 전혀 맞지 않았습니다. 다시 말해 오른쪽에는 Filter에 해당하는 정보가 없다는 것을 알 수 있습니다.
(2) Activation map(Feature map)
Filter를 사용하여 뽑아낸 숫자를 모아놓은 것을 Activation map이라고 한다고 했습니다. Activation map의 크기는 Filter의 크기와 Stride, 그리고 Padding에 의해 결정됩니다. Activation map의 크기에 대해 아는 것이 왜 중요할까요? Filter를 통해 Convolution을 하여 만든 Activation map은 본래의 이미지 크기보다 작을 수밖에 없습니다. 크기가 작아진다는 개념을 아는 것은 중요하지만 직접 구하는 것은 그리 중요치 않으므로 계산값만 알고 넘어가겠습니다.
이와 더불어 Padding의 개념을 아는 것이 중요합니다. Convolution을 자꾸 하다 보면 이미지가 자꾸 작아진다고 하였는데 Padding 값을 주어 이를 막을 수 있습니다.

위와 같은 식으로 본래 이미지의 둘레에 0으로 둘러쌀 수가 있는데 이를 Zero padding이라고 부릅니다. 이는 이미지 정보 손실을 방지함과 동시에 모서리 정보를 전달하는 기능도 합니다.
02) ReLU Layer
* 활성화 함수
[show_more more=”더 보기↓” less=”닫기”]
활성화 함수를 이용한 활성화 단계를 의미합니다.
딥러닝하기 3편. 신경망의 기초(활성화 함수):: http://blog.naver.com/htk1019/220965622077
활성화함수는 입력값을 그대로 이용하지 않고 입력 신호를 바탕으로 새로운 출력 신호로 변환하는 함수를 의미합니다. 활성화 함수를 거치게 된 신호는 활성화할지 말지 결정되어 출력신호로 다음 뉴런에 전달되게 됩니다.
[/show_more]
중요한 점은 이 Layer에서 ReLU 함수를 사용한다는 것입니다. 이는 Nonlinearity를 부여하는 역할을 합니다. Linear과 Nonlinear의 개념은 아래와 같습니다.
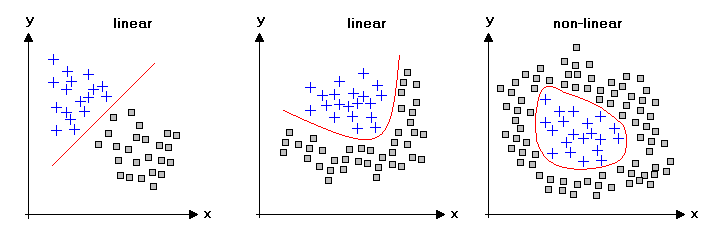
Conv 를 통과한 데이터는 덧셈, 곱셈으로만 이루어져있습니다. 다시 말해 Linear한 상태입니다. Linear할 경우 단순한 데이터 분류는 가능하지만 복잡한 데이터 분류는 힘듭니다. 따라서 CNN에서는 ReLU를 이용하여 Non-Linearity 속성을 부여하게 됩니다.
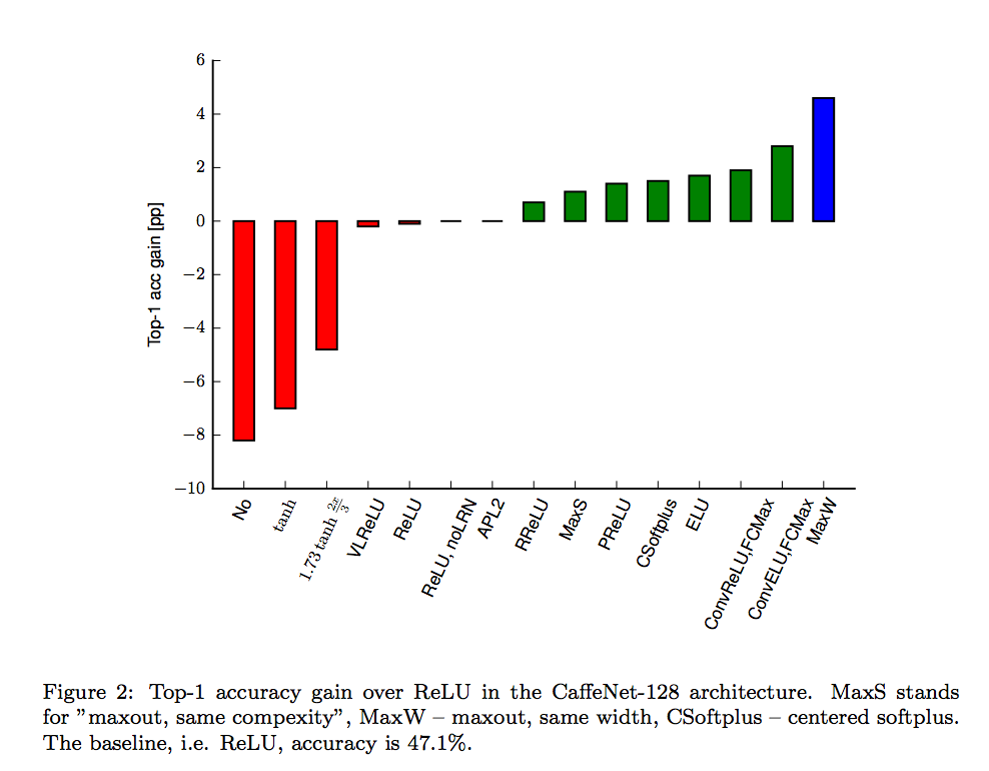
Linear하지 않은 함수를 이용하지 않을 경우 정확도가 매우 낮음을 보여주는 그래프입니다.
03) Pooling Layer
Pooling layer는 Sub-Sampling을 목적으로 구성되어져있습니다. Conv를 거친 데이터로부터 한번 더 표본을 뽑아내겠다는 소리입니다. 그것도 좋은 녀석들로만 골라서 말입니다.
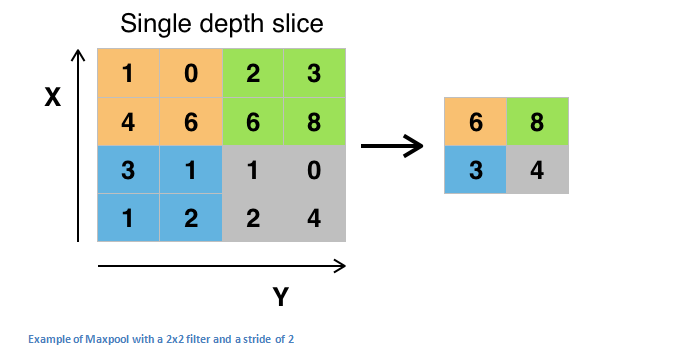
왼쪽 행렬은 Conv를 지난 Activation map입니다. Activation map의 구획을 나누어 구획에서 대표 표본을 뽑아내는 것이 Pooling의 목적입니다. 위 그림은 Pooling의 방법 중 하나인 Max pooling을 보여주는 그림입니다. Max pooling은 말 그대로 구획에서 가장 큰 값을 뽑아내는 방법입니다. Average pooling, L2-norm pooling 등이 있다고 하나 Max 가 가장 좋은 방법이라고 합니다. 아무튼, 이렇게 Pooling을 하면 크게 두 가지 효과를 얻을 수 있습니다. 첫째, 정말 꼭 필요한 데이터만 뽑아낼 수 있다는 것, 둘째, 그로 인해 데이터의 양이 작아진다는 것입니다. 예를 들어 주황색 칸에서 1, 0 등은 딱히 쓸모가 없는 값이잖아요. 또한 원본 이미지에서 맥락에 맞지 않는 약간의 노이즈가 들어갈 경우에도 Pooling 과정을 거치면 노이즈를 일부 제거하고 데이터를 학습시킬 수가 있게 됩니다.

여기까지의 결과물이 위 그림입니다.
04) Fully Connected Layer (FC layer)
마지막 FC layer에서 이전까지의 정보를 모두 모아 Softmax classification을 통해 숫자를 예측하게 됩니다.
실습
이번 실습 역시 MNIST로 시작해보도록 하겠습니다.
import tensorflow as tf
import matplotlib.pyplot as plt
import random
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
학습을 위한 셋팅을 먼저 해주시고요.
# 학습의 속도와 Epoch, 그리고 데이터를 가져올 batch의 크기를 지정해 줍니다. learning_rate = 0.001 training_epochs = 3 batch_size = 100
# 먼저 이미지의 정보를 담을 X를 placeholder로 지정해줍니다. X = tf.placeholder(tf.float32, [None, 784]) # 가져온 정보를 이미지화 하기 위하여 reshape합니다. X_img = tf.reshape(X, [-1, 28, 28, 1]) # img 28x28x1 (black/white) # 이미지의 Label 정보를 담을 Y 역시 placeholder로 지정해줍니다. Y = tf.placeholder(tf.float32, [None, 10])
기본적인 세팅은 끝났으니 본격적으로 Convolution부터 시작해보도록 하겠습니다. 우선 Filter를 만들어야 합니다.
# CNN에서 우리는 결국 제대로 된 Filter를 가진 Model을 구축해 나갈 것입니다. # 다시 말해 Filter를 학습시켜 이미지를 제대로 인식하도록 할 것입니다. # 그렇기에 Filter를 변수 W로 표현합니다. # 32개의 3 x 3 x 1의 Filter를 사용하겠다는 뜻입니다. W1 = tf.Variable(tf.random_normal([3,3,1,32], stddev=0.01))
이 Filter를 직접 적용해보도록 하겠습니다.
# 간단하게 conv2d 함수를 사용하면 됩니다. L1 = tf.nn.conv2d(X_img, W1, strides=[1,1,1,1], padding='SAME')
ReLU layer와 Pooling layer 역시 간단한 코드 한줄로 구현이 가능합니다.
L1 = tf.nn.relu(L1) L1 = tf.nn.max_pool(L1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
이 과정을 반복해줍니다.
# W2는 두번째 Conv의 Filter입니다. # 다만 이전 과정 Filter의 개수가 32개였기 때문에 # 그 숫자에 맞추어 depth를 32로 지정해줍니다. W2 = tf.Variable(tf.random_normal([3,3,32,64], stddev=0.01))
역시 Conv를 한 후에 ReLU와 Pooling을 추가하여 줍니다.
L2 = tf.nn.conv2d(L1, W2, strides=[1,1,1,1], padding='SAME') L2 = tf.nn.relu(L2) L2 = tf.nn.max_pool(L2, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
이제 마지막으로 Fully Connected Layer를 통과시켜봅시다. FC layer에서는 Softmax Classfication을 사용하여 가설과 실제 Label을 비교해보는 작업을 통해 학습이 이루어집니다.
# Softmax를 통한 FC layer를 활용하기 위해 shape를 변환해줍니다. # 위에서 L2는 일종의 X 값이라고도 볼 수 있습니다. # Softmax를 거칠 예측값(WX+b)을 만들어주기 위해 reshape 합니다. L2 = tf.reshape(L2, [-1, 7*7*64])
W, b를 설정해봅시다.
# W3를 설정하는데 Xavier initializing을 통해 초기값을 설정할 것입니다.
# reshape된 L2의 shape이 [None, 7*7*64] 였으므로
# W3의 shape은 [7*7*64, num_label]이 됩니다.
W3 = tf.get_variable("W3", shape=[7*7*64, 10], initializer = tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.random_normal([10]))
따라서 가설은 익숙한대로 이렇게 됩니다.
hypothesis = tf.matmul(L2, W3) + b
끝으로 cost와 optimizer는 간단하게 아래와 같이 설정할 수 있습니다.
# Softmax 함수를 직접 사용하는 대신에 sofmax_corss_entropy_with_logits을 사용할 수 있습니다. # 인자로 logits과 label을 전달해주면 됩니다. cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=hypothesis, labels=Y)) # 이전까지는 Gradient Descent Optimizer를 사용하였지만 # 좀 더 학습성과가 뛰어나다고 알려져있는 Adam Optimizer를 사용하겠습니다. optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
이제 세션을 만들고 실행시켜주면 됩니다.
sess = tf.Session()
sess.run(tf.global_variables_initializer())
print('Learning started. It takes sometime.')
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples / batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
feed_dict = {X: batch_xs, Y: batch_ys}
c, _ = sess.run([cost, optimizer], feed_dict=feed_dict)
avg_cost += c / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning Finished!')
끝으로 우리가 만든 학습 모델이 잘 학습되었는지 테스트를 해보도록 합시다.
# 먼저 늘 그래왔듯 accuracy op를 만들고요.
correct_prediction = tf.equal(tf.argmax(hypothesis, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# MNIST의 테스트용 이미지를 feed_dict로 전달합니다.
print('Accuracy:', sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels}))
# 랜덤하게 하나의 이미지를 정확히 맞추는지 역시 테스트가 가능합니다.
r = random.randint(0, mnist.test.num_examples - 1)
print("Label: ", sess.run(tf.argmax(mnist.test.labels[r:r + 1], 1)))
print("Prediction: ", sess.run(
tf.argmax(hypothesis, 1), feed_dict={X: mnist.test.images[r:r + 1]}))
# matplotlib을 사용하여 랜덤하게 뽑힌 이미지를 출력할 수도 있습니다.
plt.imshow(mnist.test.images[r:r + 1].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.show()