
단변수 통계(1)
Chapter 03에서 배울 내용
- 주요 분포
- 모수적 검정 5가지
- 비모수적 검정 3가지
- 선형 모델
01 주요 분포
Normal distribution
정규분포는 평균 와 표준편차
를 모수로 합니다. 측정값(Estimator)는
와
입니다.
Chi-Square distribution
카이분포는 의 정규분포를 따르는 서로 독립인
개의 랜덤변수의 합이 이루는 분포입니다. 이때의 자유도(degree of freedom, df)는
입니다.
라면
이고 다음이 성립합니다.
(one df)
개의 표준정규변수의 합:
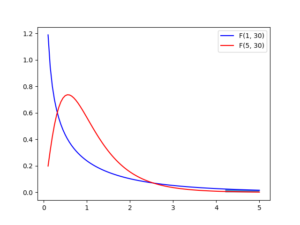
Fisher’s F-distribution
F 분포는 두 개의 독립적인 Chi 변수의 비율이 따르는 분포입니다. 일 때 다음이 성립합니다.
import numpy as np from scipy.stats import f import matplotlib.pyplot as plt fvalues = np.linspace(0.1, 5, 100) plt.plot(fvalues, f.pdf(fvalues, 1, 30), 'b-', label = "F(1, 30)") plt.plot(fvalues, f.pdf(fvalues, 5, 30), 'r-', label = "F(5, 30)") plt.legend() # cdf: Cumulative distribution function of F proba_at_f_inf_3 = f.cdf(3, 1, 30) print(proba_at_f_inf_3) # ppf(q, df1, df2): Percent point function (inverse of cdf) at q of F f_at_proba_inf_95 = f.ppf(0.95, 1, 30) print(f_at_proba_inf_95) # sf(x, df1, df2): Survival function (1 - cdf) at x of F. proba_at_f_sup_3 = f.sf(3, 1, 30) # P(F(1,30) > 3) assert proba_at_f_inf_3 + proba_at_f_sup_3 == 1 # p-value: P(F(1, 30)) < 0.05 low_proba_fvalues = fvalues[fvalues > f_at_proba_inf_95] plt.fill_between(low_proba_fvalues, 0, f.pdf(low_proba_fvalues, 1, 30), alpha=0.8, label = "P < 0.05") plt.show()
The Student’s t-distribution
이고
라면
은 다음과 같이 나타날 수 있습니다.
02 모수적 검정
Pearson correlation test: test association between two quantitative variables
이 테스트는 Pearson 상관계수와 귀무가설(Non-correlation)에 대한 p-value 값을 구해줍니다. Linear correlation coefficient는 다음과 같이 정의됩니다.
import numpy as np import scipy.stats as stats n = 50 x = np.random.normal(size=n) y = 2 * x + np.random.normal(size=n) # Compute with scipy cor, pval = stats.pearsonr(x, y)
One sample t-test
모집단의 평균이 어떠한 값과 일치하는 지를 확인하는 테스트입니다. 예를 들어 어떤 집단의 키의 평균이 1.75m인지 테스트해보도록 하겠습니다.
1) Model the data
키가 정규분포를 따른다고 가정합니다.
2) Fit: estimate the model parameters
는
의 측정치입니다.
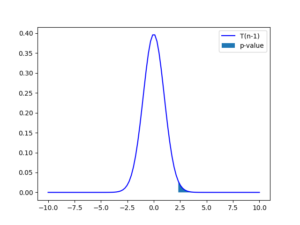
3) Test
귀무가설 하에서 는 다음과 같습니다.
import numpy as np import scipy.stats as stats import matplotlib.pyplot as plt np.random.seed(seed=42) n = 100 x = np.random.normal(loc = 1.78, scale = 0.1, size = n) tval, pval = stats.ttest_1samp(x, 1.75) tvalues = np.linspace(-10, 10, 100) plt.plot(tvalues, stats.t.pdf(tvalues, n-1), 'b-', label = "T(n-1)") upper_tval_tvalues = tvalues[tvalues > tval] plt.fill_between(upper_tval_tvalues, 0, stats.t.pdf(upper_tval_tvalues, n-1), label = "p-value") plt.legend() plt.show()
Two-sample (Student) t-test: compare two means
이 테스트는 서로 다른 두 집단의 평균이 같은지 알아보고자 할 때 사용합니다. 만약 짝지어진 두 경우(ex. 한 집단에 대하여 치료 전과 치료 후)에는 one-sample t-test of difference(Paired t-test)를 시행합니다. 두 집단의 변수의 분산이 같은 경우를 homoscedasticity라 하며, 다른 경우를 heteroscedasticity라 합니다.
1) Model data
두 랜덤변수가 각각 정규분포를 따른다고 가정합니다.
2) Fit: estimate the model parameters
각 집단의 모수를 측정합니다.
3) t-test
두 집단의 분산이 같은 경우에는 기존과 비슷합니다.
두 집단의 분산이 다른 경우에는 Welch’s t-test를 이용합니다.
import scipy.stats as stats nx, ny = 50, 25 x = np.random.normal(loc=1.76, scale=0.1, size=nx) y = np.random.normal(loc=1.70, scale=0.12, size=ny) # Compute with scipy tval, pval = stats.ttest_ind(x, y, equal_var=True)
Anova F-test(quantitative ~ categorical(> 2 levels))
Analysis of variance(ANOVA)는 여러 개의 그룹의 평균이 같은지를 비교합니다. t-test의 일반화된 형태라고 생각하면 됩니다. 하나의 변수를 기준으로 하는 one-way ANOVA에 대해 알아봅시다.
1) Model the data
한 회사가 서로 다른 세 가지의 전략을 이용한 마케팅에 돌입하였습니다. 각각의 전략에 대한 증가량이 라고 할 때 이에 대한 one-way ANOVA를 시행해 봅시다. 단, 각각의 변수는 정규분포를 따릅니다.
2) Fit: estimate the model parameters
3) F-test
ANOVA 테스트의 장점은 차이가 있는지 알아보기 위해 세 가지 전략 중 어떤 것이 차이가 있는지를 굳이 선택하지 않아도 된다는 것입니다. 그냥 한 번에 모든 집단을 검사할 수 있다는 것입니다. 하지만 그와 동시에 단점은 귀무가설(모든 집단의 평균이 같다)을 기각하게 되었을 때 어떤 집단의 평균이 다른 집단들과 다른지는 알 수 없다는 것입니다.
F 통계량은 다음과 같습니다.
“explained variance” 혹은 “between-group variability”는 다음과 같습니다.
:
번째 그룹의 평균,
:
번째 그룹의 샘플 수,
: 전체 평균,
: 전체 그룹의 수
“unexplained variance” 혹은 “within-group variability”는 다음과 같습니다.
:
번째 그룹의
번째 관측치,
: 전체 샘플 수
F-통계량은 귀무가설 하에서 자유도가 와
인 F-분포를 따릅니다. 만약 그룹간의 평균이 다를 경우에는 분자(explained variance, between-group variability)가 크기 때문에 F-통계량이 값이 크게 됩니다.
import numpy as np
import scipy.stats as stats
mu_k = np.array([1,2,3])
sd_k = np.array([1,1,1])
n_k = np.array([10,20,30])
grp = [0,1,2] # group label
n = np.sum(n_k)
label = np.hstack([[k] * n_k[k] for k in [0, 1, 2]])
y = np.zeros(n)
for k in grp:
y[label == k] = np.random.normal(mu_k[k], sd_k[k], n_k[k])
fval, pval = stats.f_oneway(y[label==0], y[label==1], y[label==2])
Chi-square(categorical~categorical)
Chi-square test는 관측 테이블(cross-table)을 이용하여 변수 사이의 독립성을 검정하는 테스트입니다. 이때의 귀무가설은 “두 변수 사이에는 연관성이 없다”, 즉 “두 변수는 독립이다”입니다.
import numpy as np
import pandas as pd
import scipy.stats as stats
canalar_tumor = np.array([1] * 10 + [0] * 5)
meta = np.array([1] * 8 + [0] * 6 + [1])
crosstab = pd.crosstab(canalar_tumor, meta, rownames=['canalar_tumor'], colnames = ['meta'])
print("Observed table:")
print("------------")
print(crosstab)
chi2, pval, dof, expected = stats.chi2_contingency(crosstab)
print("Statistics:")
print("------------")
print("Chi2 = %f, pval = %f" %(chi2, pval))
print("Expected table:")
print("---------------")
print(expected)