

Scikit-learn의 CountVectorizer를 이용한 “뉴스 그룹 분류”
이 포스트는 이전 포스트(Scikit-learn의 CountVectorizer를 이용한 “관련 게시물 찾기”)에서 이어집니다.
군집화
우리는 이전 포스트에서 “관련 게시물 찾기”를 하였습니다. 새로운 게시물이 들어왔을 때 Label이 붙어있지 않은 데이터 집합 중 가장 가까운 게시물을 찾는 작업을 알아보았습니다. 기존의 데이터가 그리 많지 않다면 이런 식으로 새로운 게시물과 기존 데이터 전체를 비교를 하면 되겠지만 만약 기존의 데이터가 이미 많은 상태라면 새로운 게시물과 기존 데이터 전부를 비교하기는 쉽지 않을 것입니다.
이러한 비교 과정을 최소화하기 위해 우리는 기존의 데이터를 ‘군집’ 형태로 미리 묶어놓을 수 있습니다. 즉, 예를 들어 100개의 데이터가 있다면 10개씩 데이터를 묶어 놓고(각 군집의 크기는 달라도 상관 없습니다.) 각 군집의 대표값만을 새로운 데이터와 비교하면 될 것입니다. 이렇게 비슷한 데이터끼리 묶어놓는 것을 군집화라고 합니다.
군집화에는 계층 군집화와 수평 군집화로 크게 2가지 종류가 있습니다. 계층 군집화는 거리가 가까운 데이터 2개씩을 묶어나가는 과정입니다. 군집 위에 군집이 생기고 다시 그 군집이 다른 군집에 속하며 계층을 이루게 됩니다. 계층 군집화의 경우 초기에 군집의 개수를 설정하지 않아도 됩니다.
수평 군집화는 초기에 계층의 개수를 설정해 놓고 기계에게 해당 데이터를 ‘몇 개’의 군집으로 분류하도록 미리 설정해놓는 것을 말합니다. 이번 포스트에서는 이 수평 군집화에 대해 다루어보도록 하겠습니다.
K평균
K평균(KMeans)은 수평 군집화를 실행하는 대표적인 알고리즘입니다.
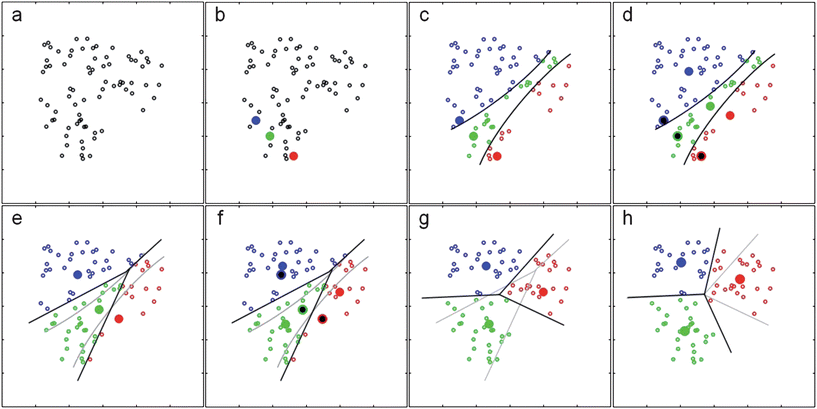
위 그림은 KMeans가 이루어지는 전형적인 예를 보여주고 있습니다.
b. 초기 군집의 개수를 3이라고 지정해놓고 시작하는 모습입니다. 그림에 표시된 파란, 초록, 빨강 점들은 임의로 찍은 점들입니다. 초기에 임의의 ‘중앙점’을 설정하고 그 후 KMeans 과정을 통해 이 중앙점을 옮겨가게 됩니다.
c. 초기 중앙점으로부터 거리가 가까운 점들을 색칠해 놓은 것입니다. 파란 점들은 다른 중앙점들보다 파란 중앙점과의 거리가 더 가까운 데이터들입니다.
d. 중앙점을 한번 이동한 후의 모습입니다. 왼쪽 하단에 위치해 있던 중앙점들이 가운데 부분으로 이동하였습니다. 이렇게 중앙점이 이동하는 기준은 바로 c에서 색칠한 점들입니다. c에서 색칠한 점들의 중앙으로 중앙점들을 이동하는 것입니다.
e. 새로 이동한 중앙점을 기준으로 데이터들을 재배치합니다. c에서는 파란 중앙점에 더 가까웠던 점들이 초록 중앙점에 더 가깝게 되었다면 해당 데이터는 이제 초록 군집에 속하게 됩니다.
f~h. 위의 과정을 반복하다보면 어느 순간 중앙점의 이동이 미미해지는 순간이 올 것입니다.(Scikit-learn에서는 이동거리가 0.0001 미만일 때 움직임이 없다고 봅니다.) 이 때 중앙점 이동을 멈추고 해당 시기의 군집을 각 데이터에 지정하고 군집 중앙점과 군집번호를 리턴합니다.
Fetch_20newsgroups
Scikit-learn의 datasets에는 여러 데이터셋이 담겨있습니다. 이번에는 fetch_20newsgroups 데이터셋에 담긴 뉴스들을 이용하여 주제를 설정하고 새로운 뉴스가 들어왔을 때 자동으로 주제를 분류해주는 작업을 해보겠습니다.
01) 데이터셋 불러오기
우선 데이터셋을 불러옵니다.
import sklearn.datasets all_data = sklearn.datasets.fetch_20newsgroups(subset='all')
사실 모든 뉴스 데이터를 분류하기에는 양이 꽤 많습니다. 일부만 이용하도록 하겠습니다.
# 먼저 가져오고 싶은 그룹을 설정합니다. group = ['comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'sci.space'] # subset 인자를 전달하여 train과 test 데이터를 각각 불러올 수 있습니다. train_data = sklearn.datasets.fetch_20newsgroups(subset='train', categories=group) test_data = sklearn.datasets.fetch_20newsgroups(subset='test', categories=group)
02) Vectorization
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
class StemmedCountVector(TfidfVectorizer):
def build_analyzer(self):
analyzer = super(StemmedCountVector, self).build_analyzer()
return lambda doc: (english_stemmer.stem(w) for w in analyzer(doc))
vectorizer = StemmedCountVector(min_df = 10, max_df=0.5, stop_words='english', decode_error='ignore')
vectorized = vectorizer.fit_transform(train_data.data)
03) 군집화(KMeans)
Scikit-learn에서 KMeans를 통해 군집화하는 과정은 매우 단순합니다. 아래의 코드 4줄만으로 KMeans 과정을 진행할 수 있습니다.
# 초기 군집 개수를 설정합니다. num_clusters = 20 from sklearn.cluster import KMeans km = KMeans(n_clusters = num_clusters, init='random', n_init=1, verbose=1) km.fit(vectorized)
이제 km에는 기존 데이터를 군집화한 정보들이 담겨있습니다.
* KMeans 알아보기
[show_more more=”더 보기 ↓” less = “닫기”]
KMeans 생성자의 인자로 여러가지를 전달할 수 있습니다.
– n_clusters: 원하는 군집의 개수
– init: 초기의 중앙점 설정 방법 {k-means++, random, nparray}
> 기본값: k-means++
– n_init: KMeans 알고리즘을 돌리는 횟수
> 기본값: 10
– verbose: 모든 과정을 다 출력할 것인지
> 기본값: 0(False)
[/show_more]
04) 새로운 뉴스 군집 설정하기
이제 새로운 뉴스가 들어왔을 때 스스로 군집을 찾아가도록 하는 과정을 알아보겠습니다.
# 새로운 게시물 new_post = "Disk drive problems. Hi, I have a problem with my hard disk. \ After 1 year it is working only sporadically now. \ I tried to format it, but now it doesn't boot any more. \ Any ideas? Thanks." # vectorization 시킨 후 new_post_vec = vectorizer.transform([new_post]) # KMeans의 predict 함수에 대입합니다. new_post_label = km.predict(new_post_vec)[0]
new_post_label에는 새로운 뉴스의 군집 번호가 담겨있습니다. [0]을 붙인 이유는 predict가 [14] 이런 형태로 반환하기 때문입니다.
이제 새로운 뉴스와 같은 군집에 속한 뉴스들을 가져와보겠습니다.
similar_indices_array = (km.labels_ == new_post_label) similar_indices = similar_indices_array.nonzero()[0]
similar_indices_array는 km.labels_ 중 new_post_label의 값과 같은 원소를 True로 리턴한 불 배열입니다(나머지는 False). 이 배열에 nonzero() 함수를 적용하게 되면 0이 아닌 원소의 “위치”를 알려주는 리스트를 리턴합니다. <fn>http://cimple.tistory.com/427</fn>
* nonzero 함수 알아보기
[show_more more=”더 보기 ↓” less = “닫기”]
import numpy as np A = np.array([1,2,0,0,0,1,5,0,1]) B = A.nonzero() print(B)
[/show_more]
끝으로 list를 만들고 list에 거리와 포스트 내용을 담아와봅시다.
similar = []
for i in similar_indices:
dist = np.linalg.norm(new_post_vec.toarray() - vectorized[i].toarray())
similar.append((dist, train_data.data[i]))
# dist가 작은 순서대로 정렬됩니다.
similar = sorted(similar)
같은 군집 내에서 거리가 가장 가까운 게시물은 인덱스 번호를 지정해줌으로써 불러올 수 있습니다.
show_at_1 = similar[0] print(show_at_1)