
연속형 확률분포
연속형 확률분포1
지수분포
확률밀도함수가 지수적으로 감소하는 확률분포
#확률밀도함수 f(x) (rate: lambda, 초기치: rate=1) dexp(x, rate) #누적분포함수 F(x) pexp(x, rate, lower.tail=T) #분위수 (p: 누적확률) qexp(p, rate, lower.tail=T) #지수 확률변수(n: 난수의 개수) rexp(n, rate)
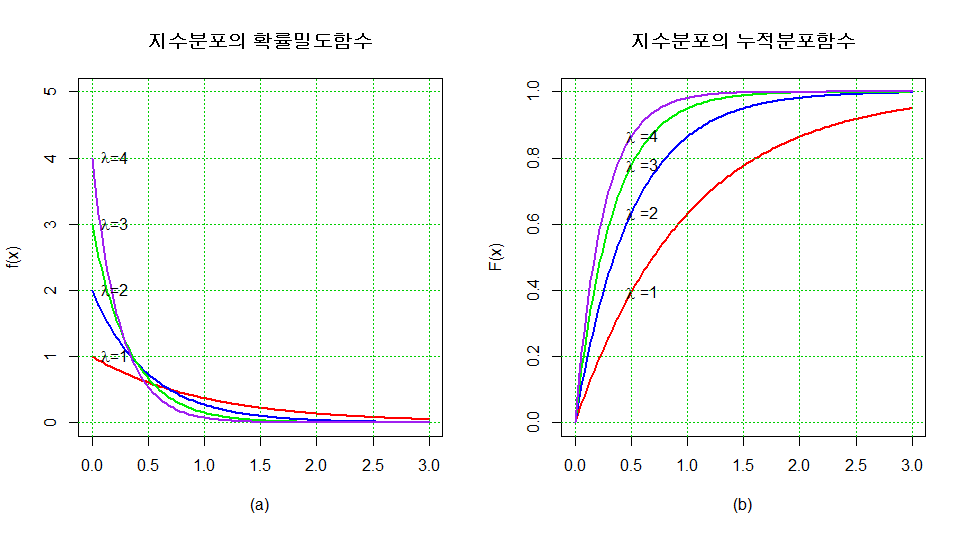
* 지수분포의 비기억(memoryless) 특성
이산형분포 중 비기억 특성을 갖는 분포는 기하분포이다.
어떤 제품의 수명이 지수분포를 따른다면, 비기억 특성에 의해 ‘이 제품이 시간 작동했다는 조건 하에서 앞으로
시간 더 작동할 확률’은 ‘새 제품이
시간 작동할 확률’과 같다는 의미가 된다.
감마분포
: 분포의 형태를 결정하는 형상모수(shape parameter)
: 단위를 결정하는 척도모수(scale parameter)
* 감마함수(gamma function)
감마함수를 부분적분하면
이 되는데 만약 가 정수
이라면
이 된다.
위의 확률밀도함수에서
이 되어야 하므로
가 된다.
만약 이라면
,
즉 인 지수분포가 된다.
#확률밀도함수 f(x) (shape: alpha, rate: 1/theta와 scale: theta 중 하나만 입력) dgamma(x, shape, (rate), scale) #누적분포함수 F(x) pgamma(x, shape, (rate), scale, lower.tail=T) #분위수 (p: 누적확률) qgamma(p, shape, (rate), scale, lower.tail=T) #감마 확률변수 (n: 난수의 개수) rgamma(n, shape, (rate), scale)
* 감마분포와 지수분포와의 관계
독립적으로 동일한 지수분포를 따르는 확률변수의 합은 감마분포를 따른다.
와이블분포(Weibull distribution)
와이블분포는 수명분포로서 가장 많이 사용된다.
: 형상모수,
: 척도모수,
이면 지수분포가 된다.
#확률밀도함수 f(x) (shape: alpha, scale: theta), 초기치 (scale=1) dweibull(x, shape, scale.default) #누적분포함수 F(x) pweibull(x, shape, scale, lower.tail=T) #분위수 (p: 누적확률) qweibull(p, shape, scale, lower.tail=T) #와이블 확률변수 (n: 난수의 개수) rweibull(n, shape, scale)
* 누적분포함수 구하기
으로 치환하면
이므로
가 되어
가 된다.
확률변수 를 수명(lifetime)인 경우로 한정하면,
는 수명이
보다 클 확률이므로, 이를 신뢰도(reliability) 함수
라 한다.
고장률(failure rate) 함수는 가 된다.
베타분포
베타분포는 두 개의 모수 와
에 따라
구간에서 다양한 분포형태를 갖는 분포로서, 베이지안 분석에서 어떤 사상의 발생확률
의 사전분포(prior)로 많이 사용된다.
#확률밀도함수 f(x) (shape1: alpha, shape2: beta, ncp: 비중심모두, 사용하지 않음) dbeta(x, shape1, shape2, ncp=0) #누적분포함수 F(x) pbeta(x, shape1, shape2, ncp=0, lower.tail=T) #분위수 (p: 누적확률) qbeta(p, shape1, shape2, ncp=0, lower.tail=T) #베타 확렬변수 (n: 난수의 개수) rbeta(n, shape1, shape2, ncp=0)
1.
임태진. R-확률통계. 생능출판; 2016.