
[NPE] Cochlear implants – Speech processing strategy
Speech processor
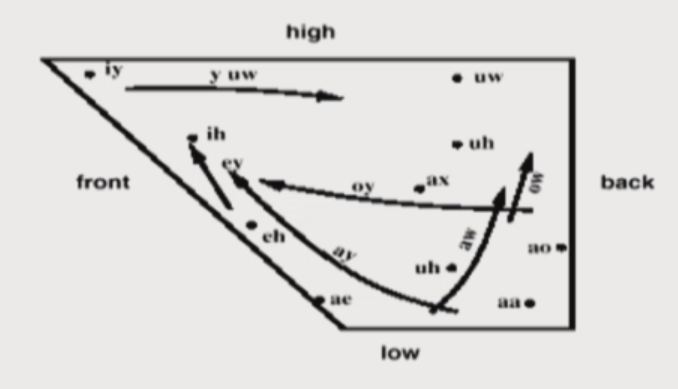
Taxonomy of Speech Sounds
Voiced or unvoiced (유성음 vs. 무성음)
- All the voewels are voiced sounds
- Consonants are voiced or unvoiced sounds
- Voiced sounds are resonant.
- Unvoiced sounds are noisy.
Vowels
- position of articulators: high, mid, low
- shoae of lips: rounded or not
-place of constriction: front, central, retroflex
Vocoder
Vocoder (Voice coder)
- reproducing an intelligible facsimile of a voice for recorded messages on telephone systems
- efficiency matters: to reduce the information content in voice messages(일정 기준으로 추출된 정보의 목소리만을 전달하는 것이 목표였다)
Channel vocoder
- analysis(encoding) / decoding(synthesis)
- a limited set of parameters from speech input in the analysis part
- The information rate required for transmission of the parameters is much less than that required for transmission of the unprocessed speech signal
Voice coding
How to extract information
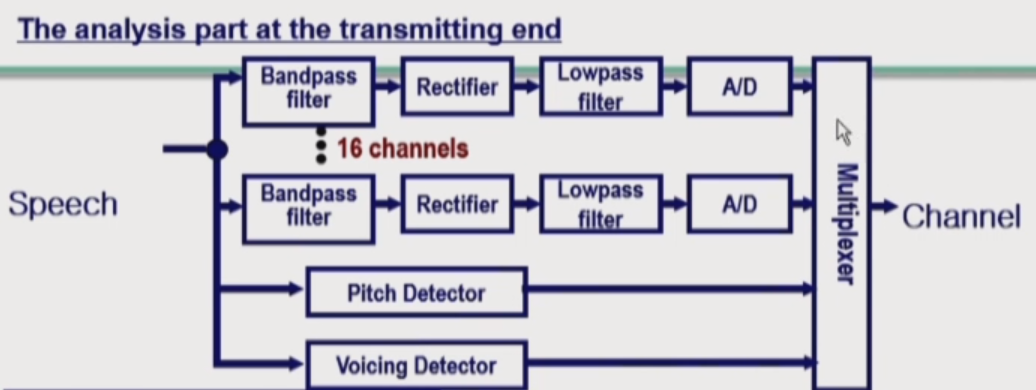
- Information about the excitation of the vocal tract is extracted with a voicing detector and with a pitch (or fundamental frequency detector)
- The voicing detector determines whetere the current speech sound is voiced or unvoiced.
- Pitch detector determines the frequency of glottal opening for voiced speech sound.
- Information about the configuration of the vocal tract is extracted with a back of bandpass filters and envelope detector.
- This analysis provides snapshots of the filtering by the vocal tract at 5~30 ms interval.
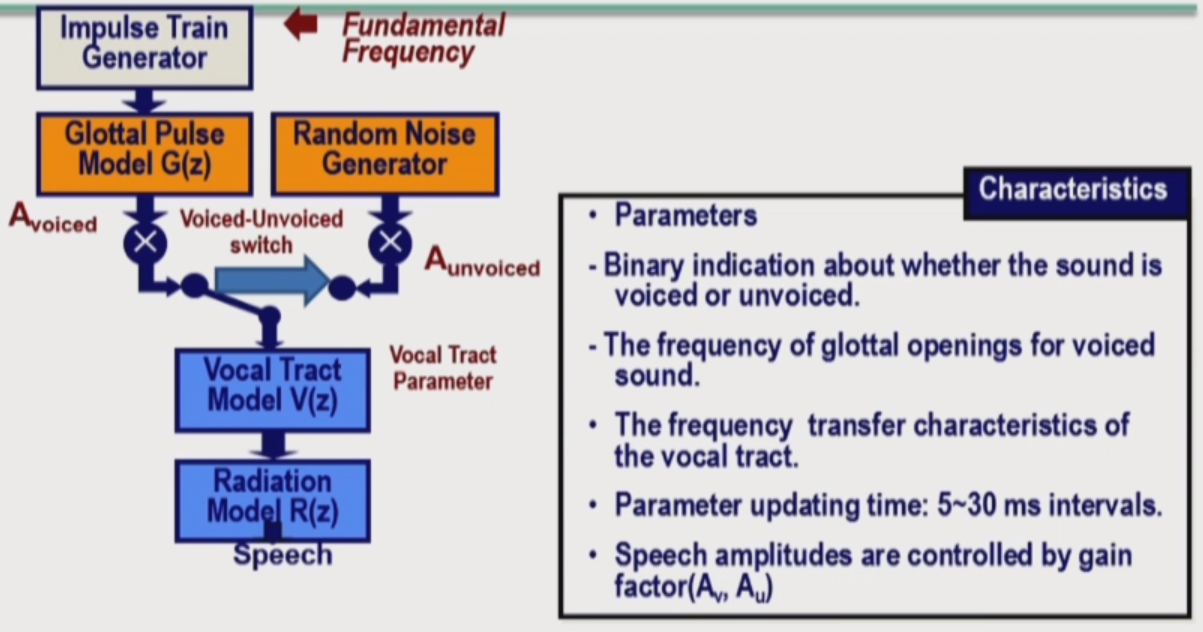
How to synthesize the sound
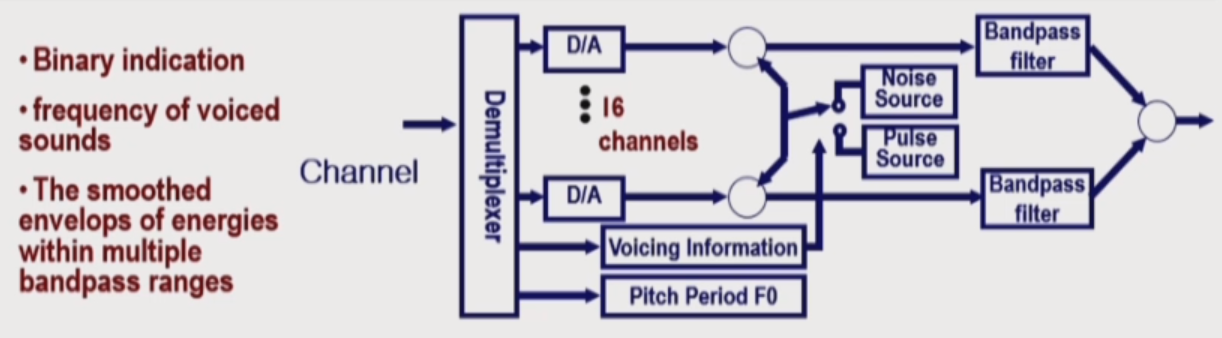
- to reconstruct the speech waveform for the listener.
- Voicing control input(binary) is used to switch between a noise source or a source of periodic pulse.
- The outputs of the multiplier blocks are envelop signals for each bandpass filters.
- A synthesized speech signal is formed by summing the outputs of the bandpass filters.
Implications for Cochlear Implants
- The amount of information that can be presented and perceived with a cochlear implant is much less.
- Perception of electrical stimuli is different from perception of acoustic stimuli. (Pitch saturation limit) : Electrical stimuli has cannot make proper pitch over 3MHz, although acoustic stimuli dosen’t have limitation on pitch saturation.
Pitch saturation limit
- Perception of lectrical stimuli is different from perception of acoustic stimuli.
- Pitch saturation limit: typically around 300 pulses/s for electrical pulses or 300Hz for electrical sinusoids. Higher rates or requencies do not produce increases in pitch.
- In normal hearing, different pitches are heard over much wider ranges of rates or frequencies, probalby through combinations of rate and place cues.
Speech Processing Strategies
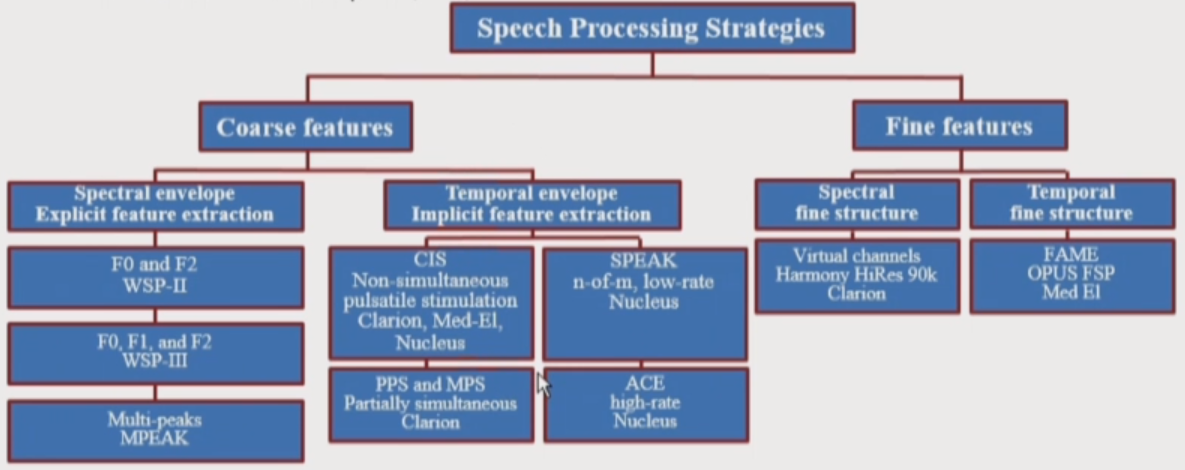
F0/F1/F2
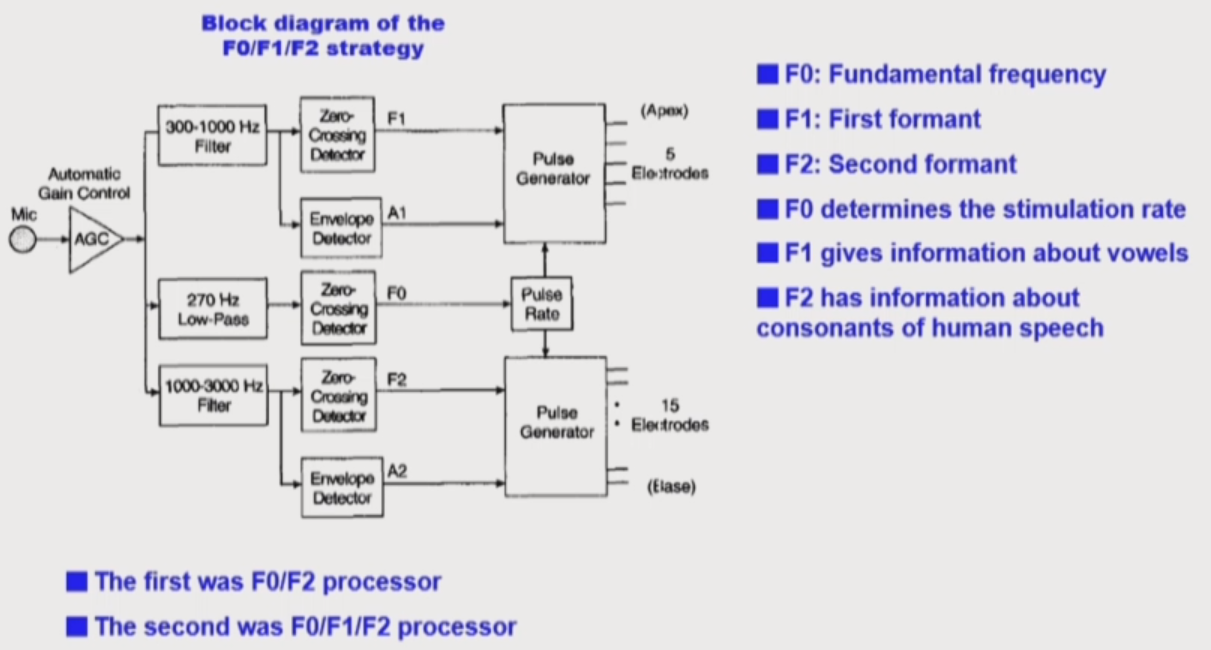
- F0: 300Hz 미만의 주파수를 이용하여 pulse rate를 본다.
- F1: 300~1,000Hz 의 주파수
- F2: 1.000~3.000Hz 의 주파수
A1, A2에 해당하는 amplitude를 pulse rate를 기반으로 modulate 해서 신호를 전달한다.
Formant: 어음에서 나타나는 peak
MPEAK
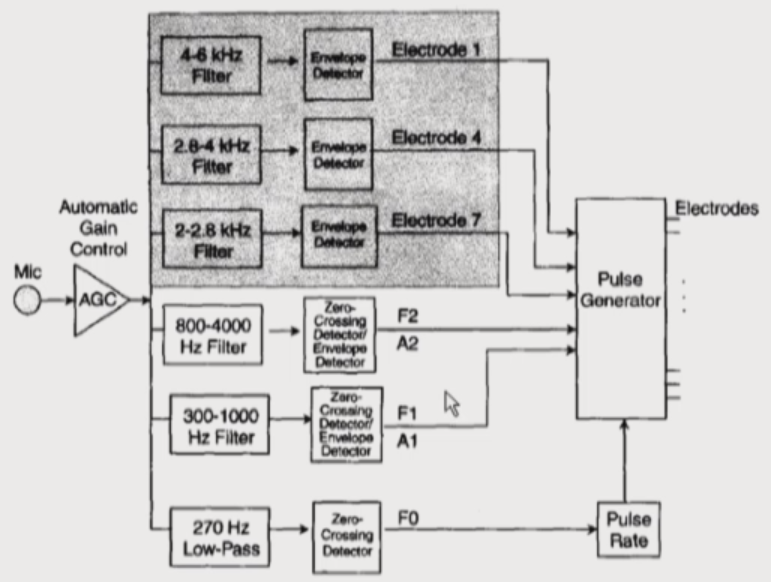
- 주파수를 좀 더 자세하게 보기 시작했다. 이전 model보다 자음을 더 강조.
- MPEAK extracts high-frequency information from the speech signal, in addition to formant information
- MPEAK strategy, as well as the F0/F1/F2 strategy, tends to make erros in formant extraction in noise environment.
이전 모델들은 feature extraction strategy이다.
CA
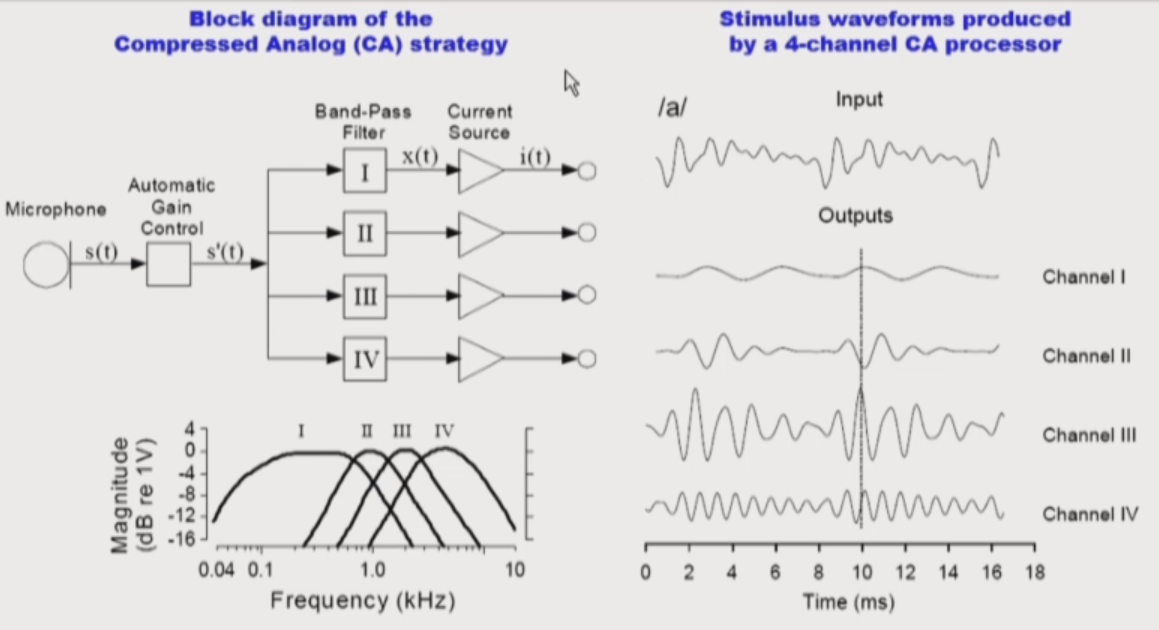
- filter만 존재한다. (Let the brain do the work)
- Stimulus was delivered simultaneously to electrodes in analog form
- Problem of the CA: Channel interaction (channel III, for example) is a main issue of CA model.
CIS
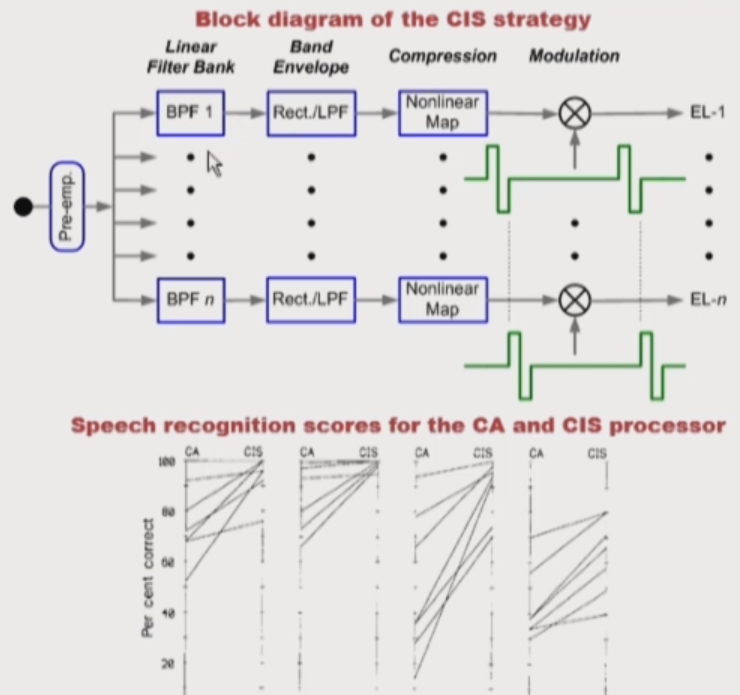
- "Pulsatile" processing + Predetermined
- Biphasic pulse trains were delivered to the electrodes in a non-simultaneous pattern
- Less channel interaction : 각 채널에 pulse가 도달하는 시간이 다르다. 동시에 pulse가 가지 않기 때문에(interleaved) SG 입장에서 보면 주변 cell들과 다른 시간에 pulse를 전달받기 때문에 channel interaction을 현저하게 줄일 수 있었다.
SPEAK, ACE
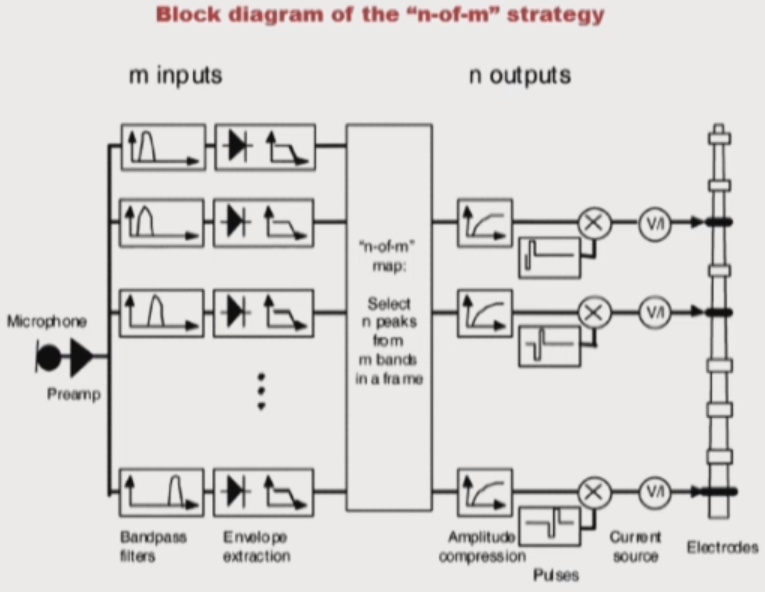
- CIS의 본격적인 활용
- m개의 filter, n개의 전극 : 더 많은 수의 filter bank를 구현해서 신호가 센 주파수 n개를 선별해서 n개의 전극을 자극한다.
- Major differences between CIS and n-of-m
- N-of-m strategy has greater number of bandpass filter.
- N-of-m strategy is based on temporal frames
- The SPEAK strategy selects 6~8 largets peaks(n) and has a fixed 250n Hz per channel rate
- The ACE strategy has a larger range of peak selection(8~12) and higher rate(900~1,200Hz) than the SPEAK strategy.
FSP
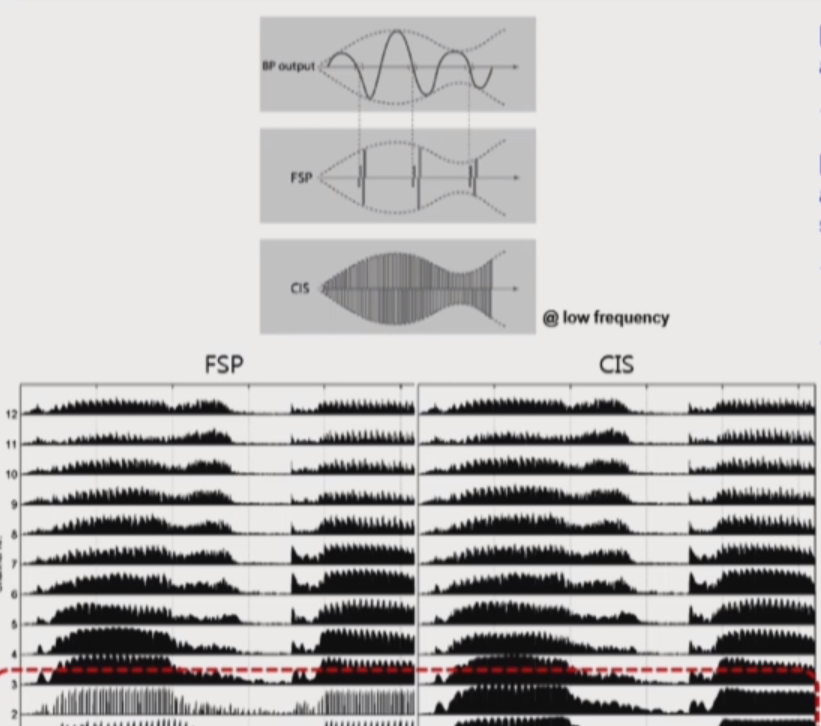
- CIS-based strategy
- 의미없는 low frequency signal을 줄임