
[Tensorflow] 03 Linear Regression 학습하기
이론
처음으로 가장 간단한 Linear Regression에 대해 배워보겠습니다.
- (x, y)의 형태로 많은 수의 데이터를 입력한다.
- 이를 x-y 그래프 상에 표시한다.
- 각각의 점들로부터의 거리가 최소인 일차함수를 찾아낸다.
01) 가설 설정
가설:
02) Cost function
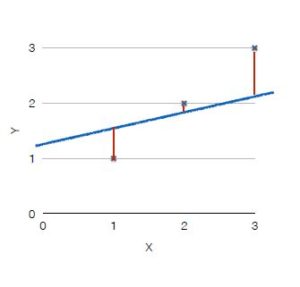
각각의 점(데이터)에서 직선까지의 거리를 구해야합니다.(정확히 말해 거리는 아니지만…)
다음과 같이 표현할 경우 양수, 음수 계산에 있어 문제가 발생할 수 있으므로 제곱의 평균을 구하도록 합시다.
03) Minimize cost
이제 의 값을 가장 작게만 만들어주면 됩니다.
실습
1. Graph 구성하기
01) 가설 설정
를 만들어 봅시다.
import tensorflow as tf # 가설 설정을 위한 변수를 설정합니다. # 머신러닝은 변수를 조정하는 학습을 시키는 것입니다. W = tf.Variable(tf.random_normal([1]), name='weight') b = tf.Variable(tf.random_normal([1]), name='bias') # 학습을 시키기 위한 데이터를 입력합니다. x_train = [1,2,3] y_train = [2,4,6] # 우리의 가설입니다. : WX + b hypothesis = W * x_train + b2
02) Cost function 설정
위에서 Cost function을
로 설정하기로 했으니깐 코딩을 짜보면 아래와 같이 되겠네요.
# cost function cost = tf.reduce_mean(tf.square(hypothesis - y_train))
** reduce_mean() 함수에 관하여
tf.reduce_mean(input_tensor, reduction_indices=None, keep_dims=False, name=None)<fn>https://tensorflowkorea.gitbooks.io/tensorflow-kr/content/g3doc/api_docs/python/math_ops.html</fn>
– 주어진 Tensor(input_tensor)의 평균을 구해주는 함수입니다. 이 때 두번 째 인자인 reduction_indices 를 참조하는데요. 이 값이 0 이라면 행끼리, 1 이라면 열끼리 연산을 해주네요. 아무런 값이 주어지지 않으면 input_tensor 의 전체를 return 합니다.<fn>https://penglover.github.io/2017/01/15/tensorflow-reduction-indices/</fn>
For example:
# 'x' is [[1., 1.]
# [2., 2.]]
tf.reduce_mean(x) ==> 1.5
tf.reduce_mean(x, 0) ==> [1.5, 1.5]
tf.reduce_mean(x, 1) ==> [1., 2.]
Args:
input_tensor: 반드시 numeric type이어야 합니다.reduction_indices: 연산의 방향입니다.None(기본값)이라면 모든 값을 연산합니다.keep_dims: If true, retains reduced dimensions with length 1. (?)name: A name for the operation (optional).
Returns:
The reduced tensor.
03) GradientDescent
위에서 설정한 cost를 줄여주는 작업에 들어갑니다. 정확히 말하면 작업에 들어가는 것이 아니라 그 작업을 실행시킬 준비를 하는 것이겠네요. TensorFlow의 train에 저장되어 있는 GradientDescentOptimizer 함수를 이용하여 optimizer라는 op를 만들고 cost를 줄이는 것이 목적이니 optimizer의 minimize를 호출시켜 우리가 값을 줄이고자하는 cost를 전달해줍니다. * GradientDescentOptimizer는 경사를 내려오기를 이용하는 알고리즘의 한 형태입니다.
# Minimize optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01) train = optimizer.minimize(cost)
** train에 관하여

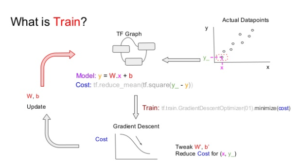
train은 하나의 훈련을 의미한다고 볼 수 있습니다. 이 정도로만 이해하고 넘어가야겠습니다. <fn>https://www.slideshare.net/KhorSoonHin/gentlest-intro-to-tensorflow-part-2-62006222</fn>
2. Session에서 실행하기
세션에서의 실행은 어렵지 않습니다.
# sess라는 세션을 만들고
sess = tf.Session()
# 세션 상에서 모든 변수를 초기화 한 후
sess.run(tf.global_variables_initializer())
# 2001번 훈련(train)을 실행(run)시킵니다.
for step in range(2001):
sess.run(train)
# 그리고 그 결과를 40번 정도만 보고자 합니다.
# 훈련은 이미 위에서 진행되었지만 각각의 op를 출력하기 위해서는
# 각각의 op 역시 실행(run) 시켜주어야 합니다.
if step % 50 == 0:
print(step, sess.run(cost), sess.run(W), sess.run(b))
3. Placeholder 이용하기
더 좋은 방법은 Session 상에서 데이터를 입력해주는 것입니다.
X = tf.placeholder(tf.float32) Y = tf.placeholder(tf.float32)
훈련용 데이터 X, Y를 placeholder로 지정하고
# Our hytothesis : WX + b hypothesis = W * X + b # cost function cost = tf.reduce_mean(tf.square(hypothesis - Y)) # Minimize optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01) train = optimizer.minimize(cost)
나머지 부분도 이렇게 바뀌어야겠지요.
# 세션 생성 및 변수 초기화
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 훈련 실행
for step in range(2001):
# 아래와 같이 리스트에 담아 한번에 op를 실행할 수도 있습니다.
# 이 때 run의 두번째 인자로 feed_dict=""를 사용하여
# 라이브러리 형태로 데이터를 전달합니다.
# 리스트에 담겨 실행된 값을 출력하기 위해 각각의 _val에 담습니다.
# train op의 값은 의미가 없으니 그냥 _ 에 담아주었네요.
# cost_val, W_val, b_val, _ = sess.run([cost, W, b, train], feed_dict={X:[1,2,3], Y:[1,2,3]})
# 다른 값을 대입할 수도 있습니다.
cost_val, W_val, b_val, _ = sess.run([cost, W, b, train], feed_dict={X:[1.1,2.1,3.1,4.1,5.1], Y:[2.3,4.3,6.3,8.3,10.3]})
if step % 50 == 0:
print(step, cost_val, W_val, b_val)
끝으로 우리의 Model이 제대로 학습되었는지 알아보기 위한 코딩은 아래와 같습니다.
# 가설(hypothesis)를 실행(run)시키면서 역시나 run의 두번째 인자를 feed_dict를 통해 전달해주었습니다.
print(sess.run(hypothesis, feed_dict={X:[5]}))